2. Einführung in Data Mining
2.1 Einführung in Data Mining
Data Mining bezeichnet die Analyse von Daten sowie die (möglichst) automatische Auswertung großer Datenmengen. Dabei kommen statistische Methoden zum Einsatz, um Beziehungen, Muster und Trends in Datenbanken zu erkennen, die sonst verborgen bleiben würden. Diese Erkenntnisse ermöglichen es Unternehmen, Probleme zu lösen, Risiken zu minimieren und neue Chancen zu identifizieren. Darüber hinaus kann mithilfe von Data Mining die Prognose zukünftiger Entwicklungen erfolgen. Auf Basis dieser Vorhersagen lassen sich fundierte Geschäftsentscheidungen treffen. Obwohl es keine einheitliche Definition von Data Mining gibt, zielt der Begriff allgemein darauf ab, Hypothesen aus Daten abzuleiten und dadurch neue Erkenntnisse zu gewinnen.
Data Mining wird häufig als Teil des umfassenderen Prozesses des Knowledge Discovery in Databases (KDD) betrachtet, konzentriert sich jedoch hauptsächlich auf spezifische Techniken zur Mustererkennung und Hypothesengenerierung. Das Ziel von Data Mining ist es, aus den vorliegenden Daten neue Einsichten zu gewinnen und daraus Hypothesen abzuleiten, die zu fundierten Entscheidungen beitragen können.
Der Begriff Mining wird in unterschiedlichen Kontexten verwendet, sei es im Bergbau oder in der Informationstechnologie. Während im Bergbau Rohstoffe wie Kohle oder Eisenerz abgebaut werden, geht es beim Data Mining darum, aus großen Datenmengen wertvolle und relevante Informationen zu extrahieren. Aufgrund dieser Analogie zum Bergbau hat sich der Begriff Data Mining in der Datenwissenschaft etabliert.
2.2 Wie funktioniert Data Mining?
Der Begriff Data Mining bezeichnet einen Prozess, der darauf abzielt, Muster, Zusammenhänge und Trends in großen Datenmengen zu identifizieren. Die Anwendung fortschrittlicher Algorithmen und analytischer Methoden auf große Informationsblöcke ermöglicht die Extraktion verborgener, jedoch nützlicher Erkenntnisse. Die gewonnenen Erkenntnisse können schließlich dazu verwendet werden, Prognosen zu treffen, Entscheidungsprozesse zu unterstützen und wertvolle Geschäftseinblicke zu gewinnen. Data Mining findet Anwendung in einer Vielzahl von Bereichen, beispielsweise im Kreditrisikomanagement, der Betrugserkennung, der Spamfilterung, der Marktsegmentierung sowie in der Meinungsforschung. Des Weiteren erfährt es als Instrument der Marktforschung eine zunehmende Relevanz, da es dazu in der Lage ist, die Stimmungen und Meinungen von Zielgruppen präzise zu erkennen und zu analysieren.
Der Data-Mining-Prozess gliedert sich in vier Schritte:
Der erste Schritt im Rahmen des Data Mining stellt die Sammlung von Daten dar. Die Datenquellen sind vielfältig und umfassen Unternehmensdatenbanken, externe Datensätze sowie Social Media. Die Speicherung erfolgt in Datenlagern, sogenannten Data Warehouses, oder in Cloud-Diensten. Die gesammelten Daten können dabei in unterschiedlichen Formaten vorliegen, wobei insbesondere zwischen strukturierten, unstrukturierten und semi-strukturierten Formaten zu unterscheiden ist. Für die nachfolgende Analyse müssen die Daten in ein für die weitere Verwendung geeignetes Format überführt werden. Eine wesentliche Herausforderung in dieser Phase besteht in der Gewährleistung der Relevanz und der hohen Qualität der gesammelten Daten, um verlässliche Ergebnisse zu erzielen.
- Datenerfassung
Im Anschluss an die Datenerhebung erfolgt die Organisation und Strukturierung der Daten. Dies impliziert die Festlegung der Kriterien zur Gruppierung, Kategorisierung und Speicherung der Daten. In dieser Phase erfolgt eine Zusammenarbeit zwischen Geschäftsanalysten, IT-Profis und Managementteams, um eine effiziente Verarbeitung und Analyse der Daten zu gewährleisten. Dazu ist eine entsprechende Organisation der Daten erforderlich. In diesem Zusammenhang kann auch die Erstellung von Datenmodellen oder -schemata von Relevanz sein, um eine übersichtliche und strukturierte Darstellung der Daten zu gewährleisten.
- Datenorganisation
Die Datenverarbeitung stellt einen wesentlichen Schritt im Analyseprozess dar, da in diesem Schritt die Daten für die eigentliche Analyse vorbereitet werden. Im Rahmen dieses Schritts erfolgt eine Bereinigung, Transformation sowie Formatierung der Daten. Zu den Aufgaben zählt die Beseitigung von Fehlern, die Ergänzung fehlender Werte sowie die Reduzierung irrelevanter Daten. Des Weiteren können Techniken wie die Normalisierung oder Standardisierung von Daten zum Einsatz kommen, um sicherzustellen, dass alle Variablen korrekt miteinander verglichen werden können. Die Automatisierung und Optimierung der genannten Datenverarbeitungsaufgaben erfolgt häufig unter Zuhilfenahme benutzerdefinierter Anwendungssoftware oder spezialisierter Datenmanagement-Tools.
- Datenverarbeitung
Nachdem die Daten verarbeitet wurden, müssen die gewonnenen Informationen für den Endnutzer verständlich und zugänglich gemacht werden. In diesem Schritt werden die Ergebnisse des Data Mining in anschaulichen Formaten wie Diagrammen, Grafiken oder interaktiven Dashboards präsentiert. Diese Visualisierungen ermöglichen es den Entscheidungsträgern, die analysierten Muster und Trends schnell zu erfassen und die richtigen Schlussfolgerungen zu ziehen. Die Präsentation kann auch in Form von Berichten oder Vorhersagen erfolgen, die Handlungsempfehlungen basierend auf den Daten bieten.
- Datenpräsentation
2.2.1 Methoden der Datenvorverarbeitung
Die Datenvorverarbeitung stellt einen wesentlichen Schritt im Data-Mining-Prozess dar, da die Qualität und Struktur der Eingangsdaten einen direkten Einfluss auf die Leistung und Genauigkeit der angewandten Algorithmen aufweisen. In der Praxis sind Daten häufig unvollständig, inkonsistent oder enthalten irrelevante Informationen, welche das Mining-Ergebnis verfälschen können. Die Hauptaufgabe der Datenvorverarbeitung besteht folglich darin, die Rohdaten in ein für die Analyse und Modellierung geeignetes Format zu transformieren. Dieser Prozess umfasst mehrere wesentliche Schritte, die im Folgenden näher erläutert werden.
Die Datenbereinigung zielt darauf ab, fehlerhafte, ungenaue oder unvollständige Daten zu identifizieren und zu korrigieren. Im Rahmen dieses Schrittes sind insbesondere fehlende Werte, Ausreißer und Duplikate zu behandeln, da diese häufig auftretende Probleme darstellen. Im Falle des Fehlens bestimmter Werte in den Datensätzen können diverse Techniken zur Ersetzung dieser Werte zum Einsatz kommen. In der Praxis haben sich verschiedene Methoden zur Imputation von fehlenden Werten etabliert. Dazu zählen die Ersetzung durch den Mittelwert, Median oder Modus der betreffenden Variablen sowie der Einsatz fortgeschrittener Techniken wie die K-Nächste-Nachbarn- oder Regressionsimputation. Bei Ausreißern, die sich signifikant vom Rest der Daten unterscheiden, besteht die Möglichkeit, diese mittels statistischer Tests oder Visualisierungsmethoden wie Boxplots zu identifizieren und gegebenenfalls zu entfernen oder anzupassen. Duplikate werden in der Regel entfernt, um die Datenintegrität zu gewährleisten und Verzerrungen in den Ergebnissen zu vermeiden.
- Datenbereinigung
In der Praxis stammen Daten oft aus unterschiedlichen Quellen und müssen miteinander integriert werden, um eine umfassende Analyse zu ermöglichen. Der Prozess kann das Zusammenführen von Datensätzen aus verschiedenen Datenbanken, Tabellen oder Formaten beinhalten. Die Herausforderung besteht in der Regel in der Harmonisierung von Datentypen, der Auflösung von Namenskonflikten sowie der Sicherstellung der Konsistenz zwischen den integrierten Datensätzen. Die Anwendung von Methoden wie der Verwendung von Schlüsselattributen oder Matching-Algorithmen unterstützt die korrekte Integration der Daten sowie die Beseitigung von Inkonsistenzen.
- Datenintegration
Die Transformation von Daten umfasst eine Vielzahl von Verfahren, welche die Rohdaten in eine Form überführen, die für die nachfolgende Analyse optimal geeignet ist. Zu den gängigen Transformationstechniken gehören:
- Daten Transformation
- Im Rahmen der Normalisierung erfolgt eine Skalierung der Werte numerischer Variablen, sodass sie in einem definierten Bereich liegen, beispielsweise zwischen 0 und 1. Dies ist insbesondere bei Algorithmen von Relevanz, die auf Entfernungsberechnungen basieren, wie beispielsweise k-Nächste-Nachbarn oder Support Vector Machines.
- Im Rahmen der Standardisierung erfolgt eine Transformation der Daten mit dem Ziel, einen Mittelwert von 0 und eine Standardabweichung von 1 zu erreichen. Dies ist von Relevanz, sofern die Verteilung der Daten signifikante Abweichungen von einer Normalverteilung aufweist.
- Im Falle kategorialer Variablen kann eine Kodierung der Daten erforderlich sein, um diese für Machine-Learning-Algorithmen nutzbar zu machen. Dabei kommen Methoden wie das One-Hot-Encoding oder das Label-Encoding zum Einsatz.
Die Datenreduktion zielt darauf ab, die Dimensionen eines Datensatzes zu reduzieren, ohne dabei wesentliche Informationen zu verlieren. Dies ist insbesondere bei umfangreichen Datensätzen von Bedeutung, da die Verarbeitung aufgrund der hohen Datenmenge komplex und ressourcenintensiv sein kann. Zu den gängigen Methoden der Datenreduktion zählen:
- Datenreduktion
- Die Hauptkomponentenanalyse (PCA) stellt eine Technik zur Reduktion der Dimensionalität dar, welche die Daten in eine kleinere Anzahl von Hauptkomponenten transformiert. Die Zusammenfassung der größten Varianz in den Daten in den Hauptkomponenten erlaubt eine effiziente Datenrepräsentation.
- Im Rahmen der Feature-Auswahl erfolgt eine Selektion derjenigen Attribute, die für das Modell von Relevanz sind. Dies kann mittels statistischer Tests oder maschineller Lernverfahren, wie beispielsweise Entscheidungsbäume, erfolgen.
Der Begriff der Datenaggregation bezeichnet die Zusammenfassung von Datenpunkten zu einer höheren Ebene. Diese Technik erweist sich insbesondere als vorteilhaft, wenn Daten in einer sehr detaillierten Form vorliegen, die für die Analyse jedoch von untergeordneter Bedeutung ist. Ein Beispiel für die Anwendung dieser Technik ist die Aggregation der täglichen Verkaufszahlen eines Produkts zu monatlichen oder jährlichen Verkaufszahlen. Dadurch lassen sich langfristige Trends erkennen.
- Datenaggregation
2.3 Data-Mining-Prozess
Der Data-Mining-Prozess umfasst mehrere Schritte, von der Definition des Geschäftsziels bis zur Extraktion wertvoller Informationen. Zunächst muss das Geschäftsziel klar definiert werden.
- Definition des Geschäftsziels oder Problems Es ist wichtig, das Hauptproblem des Unternehmens sowie alle Unterprobleme, die das Unternehmen oder Einzelpersonen zu lösen versuchen, klar zu definieren. Stakeholder und Datenwissenschaftler sollten in die Untersuchung und Entscheidungsfindung einbezogen werden. Dieser Schritt hilft dabei:
- die zu erfassenden Daten zu identifizieren,
- die Parameter festzulegen,
- die zu verwendenden Techniken auszuwählen und
- den Data-Mining-Prozess auf die Geschäftsstrategie abzustimmen.
- Datenerfassung Sobald das Geschäftsziel klar definiert ist, sollten nur die relevanten Daten erfasst werden. Diese können aus verschiedenen Quellen wie Datenbanken, Dateien oder Ordnern stammen. Es ist wichtig, diese Daten in einem einzigen Repository zu speichern, um die nächsten Schritte zu erleichtern.
- Daten vorbereiten Rohdaten können nicht direkt analysiert werden und müssen daher bereinigt und strukturiert werden. Die Vorbereitung der Daten umfasst:
- das Entfernen von Rauschen, irrelevanten und doppelten Daten,
- die Reduzierung der Dimensionalität und
- die Behandlung fehlender Werte. Diese Schritte sind entscheidend, um die Qualität und Verwendbarkeit der Daten zu gewährleisten.
- Auswahl der Merkmale und des Modells Ein wichtiger Schritt im Data-Mining-Prozess ist die Auswahl relevanter Merkmale für die Eingabe in das Modell. Dabei werden redundante oder irrelevante Merkmale eliminiert, um die Genauigkeit des Modells und die Effizienz des Trainings zu verbessern. Basierend auf:
- der Problemdefinition,
- den umgewandelten Daten und
- der bisherigen Forschung entscheiden Datenwissenschaftler, welches Modell verwendet werden soll.
- Trainieren, Bewerten und Einsetzen des Modells Die vorbereiteten Daten werden in das ausgewählte Modell eingegeben, trainiert und mit Techniken wie Validierung und Kreuzvalidierung bewertet. Um die höchste Vorhersagegenauigkeit und Effizienz zu erreichen, werden Parameter und Gewichte angepasst. Nach dem Training wird das Modell in der Produktionsumgebung eingesetzt, um Muster zu erkennen.
- Mustererkennung Auf Basis der Modellergebnisse identifizieren Datenwissenschaftler interessante Beziehungen zwischen den Daten, wie Muster, Anomalien, Korrelationen und Assoziationsregeln. Die erkannten Muster werden anhand der im ersten Schritt festgelegten Ziele bewertet.
2.4 Data-Mining-Methoden
Beim Data Mining kommt eine Vielzahl von Methoden aus den Bereichen Statistik, Informatik und maschinelles Lernen zum Einsatz. Dazu gehören unter anderem:
- Clusteranalyse
- Klassifikation
- Regression
- Assoziationsanalyse
- Neuronale Netze
Diese Techniken werden auf große Datenmengen angewandt, um Muster zu erkennen, Vorhersagen zu treffen und Zusammenhänge zwischen Daten aufzudecken. Fortschritte bei der Rechenleistung und den Algorithmen haben dazu beigetragen, dass Data Mining immer leistungsfähiger und effizienter geworden ist.
Im Folgenden werden einige der prominentesten Data-Mining-Methoden näher erläutert. Eine genauere Erklärung bestimmter Methoden ist im Kapitel Machine Learning zu finden.
2.4.1 Klassifikation
Die Klassifikation wird eingesetzt, um wichtige und relevante Informationen über Daten und Metadaten zu gewinnen. Sie hilft dabei, Daten zu klassifizieren und in verschiedene Klassen einzuteilen.
Es gibt verschiedene Kriterien, nach denen Data-Mining-Techniken eingeordnet werden können:
- Klassifizierung von Data-Mining-Frameworks nach der Art der verarbeiteten Datenquellen: Die Klassifizierung erfolgt nach der Art der verarbeiteten Daten, wie beispielsweise:
- Multimedia
- Räumliche Daten
- Textdaten
- Zeitreihendaten
- World Wide Web
- Klassifizierung von Data-Mining-Frameworks basierend auf der verwendeten Datenbank: Diese Klassifizierung basiert auf dem jeweiligen Datenmodell, wie beispielsweise:
- Objektorientierte Datenbanken
- Transaktionale Datenbanken
- Relationale Datenbanken
- Klassifizierung von Data-Mining-Frameworks basierend auf der Art des entdeckten Wissens: Die Klassifizierung hängt von der Art des entdeckten Wissens oder den Data-Mining-Funktionen ab. Beispiele:
- Diskriminierung
- Klassifizierung
- Clustering
- Charakterisierung Einige Frameworks bieten nur wenige Data-Mining-Funktionen gleichzeitig an.
- Klassifizierung von Data-Mining-Frameworks basierend auf den verwendeten Data-Mining-Techniken: Die Klassifizierung erfolgt nach dem verwendeten Datenanalyseansatz, wie zum Beispiel:
- Neuronale Netze
- Maschinelles Lernen
- Genetische Algorithmen
- Visualisierung
- Statistik
- Data-Warehouse- oder datenbankorientierte Ansätze
Zusätzlich kann der Grad der Benutzerinteraktion im Data-Mining-Verfahren berücksichtigt werden, beispielsweise:
- Abfragegesteuerte Systeme
- Autonome Systeme
- Interaktive explorative Systeme
2.4.2 Clustering
Clustering ist eine Methode zur Gruppierung von zusammenhängenden Objekten. Sie ermöglicht es, Daten durch einige wenige Cluster zu beschreiben, wodurch oft Verbesserungen in der Übersichtlichkeit und Analyse erzielt werden können. Dabei werden jedoch bestimmte Details vernachlässigt. Das Clustering modelliert die Daten durch ihre Cluster und hat seinen Ursprung in der Statistik, Mathematik und numerischen Analyse.
Aus Sicht des maschinellen Lernens beziehen sich Cluster auf verborgene Muster. Die Suche nach Clustern ist ein unüberwachtes Lernverfahren, bei dem der resultierende Rahmen ein Datenkonzept darstellt. In der Praxis spielt Clustering eine zentrale Rolle in zahlreichen Data-Mining-Anwendungen, wie zum Beispiel:
- Wissenschaftliche Datenexploration
- Text Mining
- Information Retrieval
- Räumliche Datenbankanwendungen
- Customer Relationship Management (CRM)
- Webanalyse
- Computergestützte Biologie
- Medizinische Diagnostik
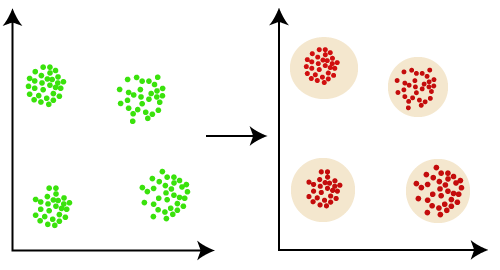
Die Clustering-Analyse ist eine Data-Mining-Technik zur Identifizierung ähnlicher Daten. Sie hilft dabei, Unterschiede und Gemeinsamkeiten zwischen den Daten zu erkennen. Clustering ist der Klassifikation ähnlich, jedoch werden hierbei Datenpakete basierend auf ihren Ähnlichkeiten gruppiert.
2.4.3 Regression
Die Regressionsanalyse ist ein Data-Mining-Verfahren zur Ermittlung und Analyse der Beziehung zwischen Variablen basierend auf dem Einfluss eines anderen Faktors. Sie wird verwendet, um die Wahrscheinlichkeit einer spezifischen Variable vorherzusagen. Regression ist in erster Linie eine Methode zur Planung und Modellierung.
Ein Beispiel: Mit Regression können die Kosten eines Produkts oder einer Dienstleistung oder andere Variablen vorhergesagt werden. Sie wird in verschiedenen Branchen eingesetzt, unter anderem für:
- Analyse von Geschäfts- und Marketingverhalten
- Trendanalysen
- Finanzielle Prognosen
Funktionsweise der Regression
Bei der Regression wird eine Gerade oder Kurve an eine große Anzahl von Datenpunkten angepasst, wobei der Abstand zwischen den Datenpunkten und der Kurve minimiert wird. Die am häufigsten verwendeten Regressionstypen sind:
- Lineare Regression
- Logistische Regression
Darüber hinaus existieren weitere Regressionstypen, die je nach Datensatz und Anforderungen angewendet werden können.
Eigenschaften und Einschränkungen
Die Regression kann Vorhersagen für abhängige Datensätze liefern, die durch unabhängige Variablen ausgedrückt werden. Jedoch hat diese Methode Einschränkungen:
- Die Vorhersagen sind oft nur für einen begrenzten Zeitraum gültig.
- Es gibt Annahmen wie die Unabhängigkeit der Variablen und die Normalverteilung der Daten.
Ein Beispiel: Wenn zwei Variablen, A und B, eine gemeinsame Verteilung (bivariate Verteilung) aufweisen, können sie unabhängig erscheinen, aber dennoch korrelieren. In solchen Fällen sind die Analyse und Nutzung der Randverteilungen von A und B entscheidend.
Vorbereitung und Analyse
Vor der Durchführung einer Regression sollten die Daten sorgfältig analysiert und Voruntersuchungen durchgeführt werden, um sicherzustellen, dass die Methode anwendbar ist. Wenn die Annahmen der Regression nicht erfüllt sind, können nichtparametrische Tests eine Alternative darstellen.
2.4.4 Association Rule Mining
Association Rule Mining ist eine einfache, aber leistungsstarke Technik zur Entdeckung verborgener Muster zwischen Attributen in großen Datensätzen. Sie wird häufig in der Warenkorb-Analyse eingesetzt. Dabei identifiziert der Algorithmus Produkte, die oft gemeinsam gekauft werden, und wandelt diese Kombinationen in Regeln um, die das Einkaufsverhalten der Kunden beschreiben.
Ein Beispiel: Wenn Produkte häufig zusammen gekauft werden, kann diese Information genutzt werden, um diese Produkte nebeneinander zu platzieren. Ein weiteres Beispiel ist die Liste von Produktempfehlungen, die Online-Käufern angezeigt wird, wenn sie ein bestimmtes Produkt betrachten.
Darüber hinaus bietet Rule Mining auch in anderen Bereichen der Datenverwaltung einer Organisation Mehrwert, wie zum Beispiel:
- Untersuchung der Datenstruktur
- Unterstützung bei der Belegung von Formularfeldern mit Prognosen
- Überprüfung der Einhaltung von Regeln über verschiedene Datenquellen hinweg
Funktionsweise
Der Algorithmus des Rule Minings leitet Assoziationsregeln aus relationalen Daten ab. Diese Regeln geben an, mit welcher Wahrscheinlichkeit ein bestimmter Wert auftritt, abhängig davon, ob andere Werte vorhanden sind. Die Regeln werden in Form von WENN-DANN-Aussagen (Antezedens → Konsequens) dargestellt. Dabei:
- Antezedens: Bedingung (z. B. gekaufte Artikel)
- Konsequens: Ergebnis (z. B. empfohlene Artikel)
Assoziationsregeln werden aus dem Datensatz abgeleitet und sorgfältig anhand bestimmter Metriken bewertet, um die Leistungsfähigkeit der Algorithmen zu beurteilen.
Beispiel-Tabelle
In der folgenden Tabelle werden Transaktionen mit gekauften Artikeln betrachtet:
| Transaktion ID | Gekaufte Artikel |
|---|---|
| 1 | Item1, Item2 |
| 2 | Item1, Item3, Item4, Item5 |
| 3 | Item2, Item3, Item4, Item6 |
| 4 | Item1, Item2, Item3, Item4 |
| 5 | Item1, Item2, Item3, Item6 |
Anwendung
- Basierend auf der Analyse solcher Transaktionsdaten kann z. B. die Regel abgeleitet werden: WENN Item1 und Item2 gekauft wurden, DANN wird auch Item3 häufig gekauft.
- Diese Information kann genutzt werden, um:
- Produktempfehlungen in Online-Shops zu verbessern
- Verkaufsstrategien im stationären Handel zu optimieren
2.4.4.1 Support
Support ist das Verhältnis der Transaktionen im Datensatz, die eine spezifische Elementgruppe enthalten. Er gibt an, wie häufig die Elementgruppe in den Daten erscheint. Höhere Supportwerte weisen darauf hin, dass die Regel häufiger oder bedeutender im Datensatz ist. Regeln mit niedrigem Support gelten hingegen als weniger relevant.
Beispiel aus der obigen Tabelle
- Höherer Supportwert: In der Tabelle sind fünf Transaktionen aufgeführt, und Item4 kommt in drei von fünf Transaktionen vor.
- Niedriger Supportwert: Die Elementgruppe
\{Item2, Item6\}tritt zusammen in zwei von fünf Transaktionen auf.
2.4.4.2 Confidence
Confidence bezeichnet das Verhältnis der Anzahl von Transaktionen, die sowohl das Antezedens als auch das Konsequens enthalten, zur Anzahl der Transaktionen, die nur das Antezedens enthalten.
Wichtig: Confidence ist nicht symmetrisch. Das bedeutet, dass die Zuversicht für X → Y nicht gleich der Zuversicht für Y → X ist.
Die folgende Grafik illustriert die Berechnung der Confidence:
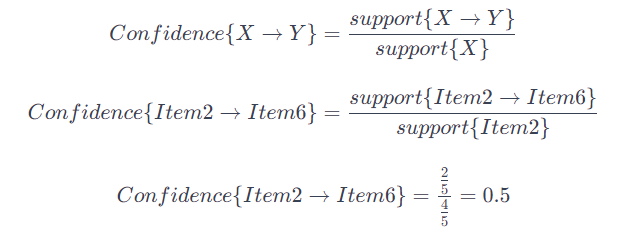
2.4.4.3 Lift
Lift misst, wie stark das Antezedens das Konsequens beeinflusst, im Vergleich zu einer unabhängigen Beziehung zwischen den beiden Ereignissen. Es quantifiziert, wie viel wahrscheinlicher das Konsequens auftritt, wenn das Antezedens gegeben ist, verglichen mit dessen Auftreten ohne das Antezedens.
Beispiel
Die folgende Grafik veranschaulicht die Berechnung des Lifts:

2.4.5 Anomalieerkennung
Die Anomalieerkennung, auch Ausreißererkennung genannt, umfasst die Identifikation ungewöhnlicher Muster oder Beobachtungen in Daten, die vom normalen Verhalten abweichen. Sie findet Anwendung in Bereichen wie Betrugserkennung, Netzwerksicherheit und Systemüberwachung.
Es gibt verschiedene Ansätze und Techniken, die je nach Datenmerkmalen und Anwendungsanforderungen eingesetzt werden können:
- Statistische Ansätze Basieren auf Methoden wie Durchschnitt, Varianz und Standardabweichung. Anomalien werden anhand von Abweichungen von den statistischen Eigenschaften der Daten identifiziert.
- Clusteranalyse Gruppiert ähnliche Datenpunkte in Cluster und identifiziert Datenpunkte, die sich von diesen Clustern unterscheiden, als Anomalien.
- Dichte-basierte Methoden Berücksichtigen die Dichte der Datenpunkte in einem bestimmten Raum. Punkte in Bereichen mit niedriger Dichte gelten als Anomalien.
- Machine-Learning-Methoden Nutzen überwachte oder unüberwachte Lerntechniken. Klassifikationsalgorithmen können trainiert werden, um zwischen normalen und anomalen Daten zu unterscheiden.
- Zeitreihenanalyse Identifiziert ungewöhnliche Muster oder Ausreißer in zeitlich geordneten Daten, speziell bei datenbasierten Zeitreihen.
Obwohl die Anomalieerkennung ein wichtiger Bestandteil des Data Mining ist, gibt es Herausforderungen, die bewältigt werden müssen:
- Ungleichgewichtene Daten Anomale Ereignisse treten selten auf, was die Effektivität der Erkennung erschweren kann.
- Hochdimensionale Daten In einem hochdimensionalen Raum sind Anomalien weniger offensichtlich, was die Analyse erschwert.
- Kontextabhängigkeit Ein Ereignis kann in einem Kontext als normal und in einem anderen als anormal gelten. Die Berücksichtigung des Kontexts ist entscheidend.
- Ausreißer und Robustheit Ausreißer können Modelle zur Anomalieerkennung beeinflussen. Robuste Methoden sind notwendig, um Verzerrungen zu vermeiden.
Anwendungen der Anomalieerkennung
Die Anomalieerkennung wird in einer Vielzahl von Bereichen eingesetzt, darunter:
- Betrugserkennung im Bank- und Finanzwesen.
- Netzwerksicherheit zur Erkennung von Intrusionen und Sicherheitsverletzungen.
- Medizinische Datenanalyse zur Diagnose von Krankheiten anhand ungewöhnlicher Muster.
- Qualitätskontrolle in der Fertigung, um fehlerhafte Produkte zu identifizieren.
- Technische Systemüberwachung, um Systemausfälle oder ungewöhnliches Verhalten vorherzusagen.
2.4.6 Sequenzielles Mustermining
Das sequenzielle Mustermining ist eine Technik zur Entdeckung von Mustern, die in Sequenzen oder zeitbasierten Daten auftreten. Diese Methode wird häufig in Bereichen wie der Analyse von Kundenverhaltenssequenzen (z. B. Website-Klickpfade) oder der Vorhersage sequenzieller Ereignisse (z. B. Börsentrends) eingesetzt.
Sequenzielles Mustermining umfasst eine Vielzahl von Techniken, die je nach Datenmerkmalen und Anwendungsanforderungen verwendet werden können:
- Frequenzbasiertes Mustermining Ziel ist es, häufig vorkommende Sequenzmuster zu identifizieren. Algorithmen wie Apriori oder FP-Growth helfen dabei, die häufigsten Sequenzen in den Daten zu entdecken.
- Sequenzklassifikation Entwicklung von Modellen, die Sequenzen in vordefinierte Klassen oder Kategorien einteilen.
- Clustering von Sequenzen Gruppierung ähnlicher Sequenzen zur Bildung von Datenclustern, um Gemeinsamkeiten und Muster zu identifizieren.
- Assoziationsregeln in Sequenzen Nutzung von Assoziationsregeln, um Zusammenhänge zwischen verschiedenen Ereignissen innerhalb von Sequenzen zu identifizieren. Dies hilft, Beziehungen zwischen aufeinanderfolgenden Ereignissen zu verstehen, ähnlich wie bei der traditionellen Assoziationsregelbildung.
Die Anwendung des sequenziellen Mustermining steht vor einigen Herausforderungen:
- Lange Sequenzen Die Analyse langer Sequenzen kann rechnerisch aufwendig sein und erfordert spezialisierte Algorithmen.
- Hohe Dimensionalität Sequenzen können viele Variablen enthalten, was die Identifikation relevanter Muster erschwert.
- Rauschen und Irrelevanz Daten können irrelevante Informationen oder Rauschen enthalten, was die Genauigkeit der Ergebnisse beeinträchtigen kann.
- Variable Längen der Sequenzen Sequenzen können unterschiedliche Längen aufweisen, was zusätzliche Anpassungen bei der Analyse erfordert.
Sequenzielles Mustermining wird in verschiedenen Bereichen eingesetzt, darunter:
- Kundenverhaltensanalyse: Identifikation typischer Klickpfade oder Kaufsequenzen.
- Zeitreihenanalyse: Vorhersage von Börsentrends oder anderen zeitbasierten Ereignissen.
- Medizinische Diagnostik: Analyse von Symptommustern oder Krankheitsverläufen.
- Betrugserkennung: Erkennung ungewöhnlicher Sequenzen in Finanz- oder Transaktionsdaten.
Diese Technik ermöglicht es, verborgene Muster in Sequenzen zu erkennen und wertvolle Einblicke in zeitbasierte Prozesse zu gewinnen.
2.4.7 Textmining
Ein wichtiger Bereich des Data Mining, der sich mit der Extraktion nützlicher Informationen, Muster oder Kenntnisse aus unstrukturierten Textdaten befasst, ist das Textmining, auch bekannt als Textanalyse oder Textdatenanalyse. Angesichts der stetig wachsenden Menge an digitalen Textdaten in Form von E-Mails, Social Media, Webseiten, wissenschaftlichen Publikationen und vielem mehr hat Textmining eine herausragende Bedeutung erlangt.
Text Mining umfasst eine Vielzahl von Techniken, die die Extraktion und Analyse von Informationen aus Textdaten zum Ziel haben. Diese Techniken reichen von der Textvorverarbeitung, der Tokenisierung und der Segmentierung bis hin zur Worthäufigkeitsanalyse, der Sentiment-Analyse und der Themenmodellierung. Bei der Textvorverarbeitung geht es um die Bereinigung und Normalisierung von Textdaten, während bei der Tokenisierung und Segmentierung der Text in sinnvolle Einheiten wie Wörter, Sätze oder Absätze zerlegt wird. Die Worthäufigkeitsanalyse umfasst die Berechnung der Häufigkeit von Wörtern in einem Textkorpus, während die Sentimentanalyse die Analyse des emotionalen Gehalts von Texten umfasst.
Text Mining ist mit verschiedenen Herausforderungen konfrontiert, die die Effizienz und Genauigkeit der Analyse beeinflussen können. Dazu gehören unstrukturierte Daten zu verarbeiten, die semantische Vielfalt von Texten, die Skalierbarkeit von Text Mining Algorithmen und die sprachliche Vielfalt von Textdaten.
Text Mining wird in vielen Anwendungen eingesetzt, wie z.B. Informationsextraktion, Suchmaschinenoptimierung, Kundenfeedbackanalyse, medizinische Textanalyse und viele mehr. Durch den Einsatz von Text Mining Techniken können wertvolle Erkenntnisse aus Textdaten gewonnen werden, die Entscheidungsprozesse unterstützen, Trends erkennen und Einblicke in verschiedene Bereiche ermöglichen.
2.4.8 Spatial Data Mining
Spatial Data Mining ist ein wichtiger Bereich des Data Mining, der sich mit der Informationsgewinnung aus räumlichen Daten befasst. Spatial Data Mining hat mit der zunehmenden Verfügbarkeit von Geodaten aus verschiedenen Quellen wie Satellitenbildern, GPS-Daten, Geoinformationssystemen (GIS) und sozialen Medien an Bedeutung gewonnen.
Spatial Data Mining umfasst eine Vielzahl von Methoden, die darauf abzielen, Muster, Trends und Beziehungen in räumlichen Daten zu erkennen. Dazu gehören Clustering, Klassifikation, Mustererkennung und die Identifikation von Assoziationsregeln.
Die Analyse und Interpretation raumbezogener Daten ist mit verschiedenen Herausforderungen verbunden. Diese sind unter anderem mit der Heterogenität der Daten, dem Maßstab, der Komplexität und der Interpretierbarkeit räumlicher Daten verbunden.
Spatial Data Mining wird in einer Vielzahl von Anwendungen eingesetzt, unter anderem in der Stadtplanung, in der Umweltüberwachung, im Katastrophenmanagement und im standortbezogenen Marketing.
2.5 Warum ist Data Mining wichtig?
Wie aus den folgenden Abschnitten ersichtlich ist, ist Data Mining von großer Bedeutung für die Gewinnung wertvoller Erkenntnisse aus großen Datenmengen. Doch was bedeutet das genau? Unternehmen und Organisationen können durch die Anwendung von Data-Mining-Techniken Muster, Trends und Beziehungen in ihren Daten identifizieren. Diese Erkenntnisse können ihnen helfen, bessere Entscheidungen zu treffen, Risiken zu minimieren und Chancen zu erkennen. Data Mining ermöglicht es, komplexe Zusammenhänge zu verstehen und vorausschauende Analysen durchzuführen. Dies ist in einer zunehmend datengetriebenen Welt von entscheidender Bedeutung, da es dazu beitragen kann, die Effizienz zu steigern, Kosten zu senken und Wettbewerbsvorteile zu erlangen. Die Vorteile von Data Mining erstrecken sich über verschiedene Bereiche wie:
- Kundenbedürfnisse erkennen und besser verstehen: Durch die Analyse von Kundenverhalten und -präferenzen können Unternehmen ihre Angebote besser auf die Bedürfnisse ihrer Zielgruppen zuschneiden und somit ihre Kundenzufriedenheit steigern.
- Genaue Vorhersagen für die Zukunft erstellen: Data Mining ermöglicht es, historische Daten zu analysieren und Modelle zu entwickeln, die zukünftige Ereignisse und Trends prognostizieren können, was Unternehmen dabei unterstützt, sich besser auf zukünftige Entwicklungen vorzubereiten.
- Zeitreihenprognosen erstellen: Durch die Analyse von zeitabhängigen Daten können Unternehmen präzise Prognosen über zukünftige Entwicklungen und Trends in verschiedenen Bereichen wie Verkaufszahlen, Finanzmärkten oder Wetterbedingungen treffen.
- Trends und Anomalien frühzeitig erkennen: Data Mining hilft Unternehmen dabei, Muster und Anomalien in ihren Daten zu identifizieren, die auf wichtige Trends oder potenzielle Probleme hinweisen können, bevor sie sich vollständig manifestieren.
- Texte und Bilder maschinell verarbeiten: Durch den Einsatz von Text Mining und Bilderkennung können Unternehmen große Mengen unstrukturierter Daten analysieren und wertvolle Erkenntnisse gewinnen, die sonst möglicherweise unentdeckt bleiben würden.
- Entscheidungsprozesse stützen: Data Mining liefert Unternehmen wertvolle Einblicke, die sie bei der Entscheidungsfindung unterstützen, indem sie Daten-basierte Empfehlungen und Prognosen liefern, die als Grundlage für strategische Entscheidungen dienen können.
- Hypothesen validieren: Durch die Analyse von Daten können Unternehmen bestehende Hypothesen überprüfen und validieren, was zu einem tieferen Verständnis ihrer Geschäftsprozesse und Kunden führen kann.
- Geschäftsprozesse optimieren: Durch die Identifizierung von Effizienzsteigerungspotenzialen und Optimierungsmöglichkeiten können Unternehmen ihre Geschäftsprozesse verbessern und Kosten senken, was letztendlich zu einer Steigerung der Wettbewerbsfähigkeit führt.
2.6 Was ist der Unterschied zwischen Data Mining und Machine Learning?
Data Mining und maschinelles Lernen werden oft als Synonyme betrachtet, obwohl sie einzigartige Prozesse sind. Beide sind nützlich, um Muster in großen Datensätzen zu erkennen, arbeiten jedoch sehr unterschiedlich.
Data Mining ist der Prozess, Muster in Daten zu finden. Es trägt dazu bei, Fragen zu beantworten, von denen wir nicht wussten, dass wir sie stellen mussten, indem es proaktiv nicht intuitiv erkennbare Datenmuster durch Algorithmen identifiziert. Zum Beispiel kaufen Verbraucher, die Erdnussbutter kaufen, wahrscheinlich auch Küchenrollen. Die Anwendung dieser Erkenntnisse auf Geschäftsentscheidungen erfordert jedoch weiterhin menschliche Beteiligung.
Machine Learning ist der Prozess, bei dem einem Computer beigebracht wird, wie Menschen lernen. Dabei lernen Computer, Wahrscheinlichkeiten zu bestimmen und Vorhersagen aufgrund ihrer Datenanalyse zu treffen. Obwohl maschinelles Lernen manchmal Data Mining als Teil seines Prozesses verwendet, erfordert es letztendlich keine häufige menschliche Beteiligung auf kontinuierlicher Basis. Zum Beispiel verlässt sich ein selbstfahrendes Auto beim Data Mining, um zu bestimmen, wo es anhalten, beschleunigen und abbiegen soll.